本文最后更新于524 天前,其中的信息可能已经过时.
部署过程
上篇文章讲了阿里的CosyVoice模型的搭建,这篇文章就讲阿里的SenseVoice语音转文本模型的搭建。
1.安装CUDA和cuDNN
-
CUDA下载地址:https://developer.nvidia.com/cuda-12-3-0-download-archive
-
cuDNN下载地址:cuDNN Archive | NVIDIA Developer
-
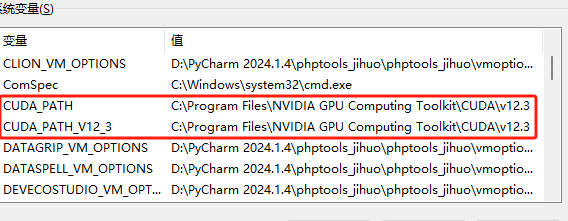
确认环境变量,一般CUDA安装完成会自动配置环境变量,如果没有就手动添加环境变量。

-
下载完cuDNN后解压文件夹,将cuDNN根目录下的所有文件复制到CUDA文件夹的根目录
-
配置cuDNN的环境变量
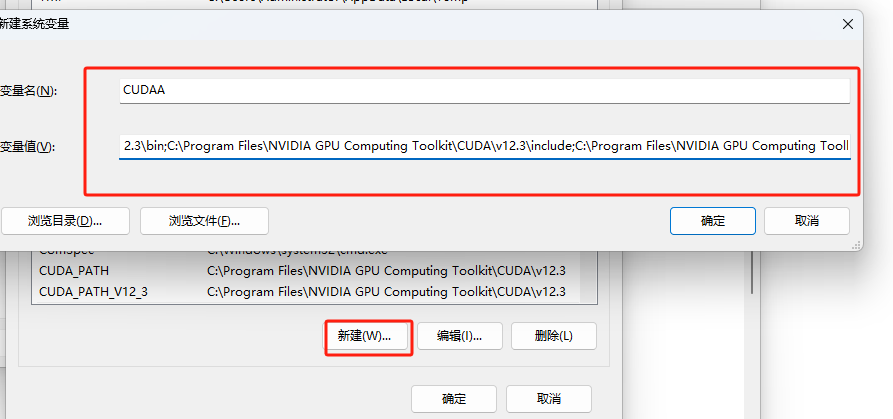
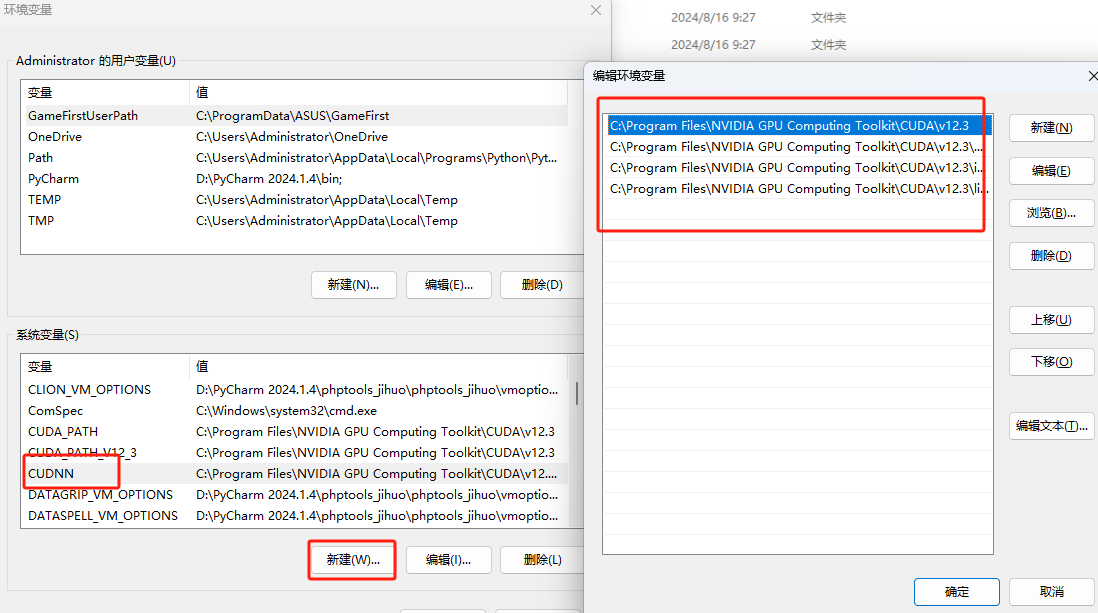
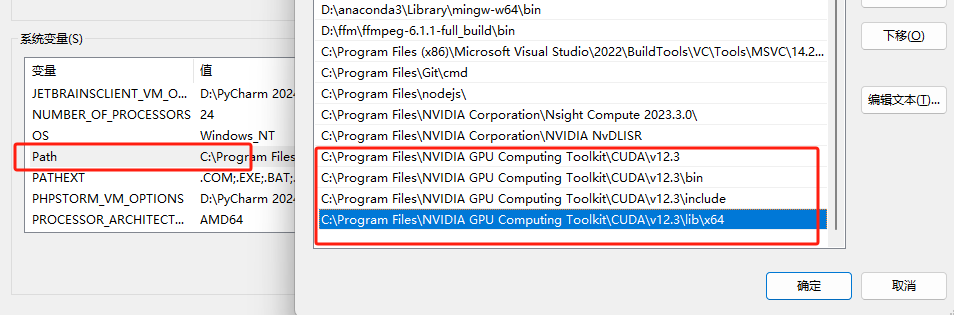
- 在系统变量中新建一个CUDNN变量
- 将CUDA的根目录,bin目录,include目录还有lib下的x64目录添加进去。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.3 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.3\bin C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.3\include C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.3\lib\x64 刚新建时要用分号将目录分开- 将这个环境变量同时添加到Path变量中
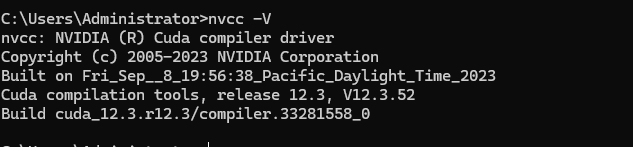
- 打开命令行输入
nvcc -V,如果正常返回版本号就安装成功了
2.部署项目
1.下载代码
使用git命令拉取代码
git clone https://github.com/FunAudioLLM/SenseVoice.git或直接在github下载源码到本地然后解压
下载地址:https://github.com/FunAudioLLM/SenseVoice/archive/refs/heads/main.zip
2.创建conda环境
进入项目目录打开终端创建conda环境并启动
conda create -n sensevoice python=3.8
conda activate sensevoice 3.安装依赖
更改requirements.txt内容如下才能调用GPU,使用cpu不用更改
--extra-index-url https://download.pytorch.org/whl/cu118
torch==2.0.1+cu118
torchaudio==2.0.2
modelscope
huggingface
huggingface_hub
funasr>=1.1.2
numpy<=1.26.4
gradio使用清华源安装依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --extra-index-url https://download.pytorch.org/whl/cu1184.下载模型
git clone https://www.modelscope.cn/iic/SenseVoiceSmall.git5.启动项目
python webui.py也可以创建.bat的启动文件,下次启动只需双击启动文件即可打开网页。
@echo off
call conda activate sensevoice
start python webui.py && start http://127.0.0.1:7860/
pause